概览
课件
课程连接
https://www.bilibili.com/video/BV1iW411d7hd?p=1
概览 overview

- 课程主题
- 五个真实的场景
- 该课程如何融入 CS/ECE 课程
- 学术诚信
课程主题 course theme

抽象是好的,但不要忘记现实
- 大多数 CS 和 CE 课程强调抽象
- 抽象数据类型
- 渐近分析
- 这些抽象有其局限性
- 特别是在存在错误的情况下
- 需要了解底层实现的细节
- 从参加 213 获得的有用结果
- 成为更高效的程序员
- 能够有效地发现并消除错误
- 能够理解并调整程序性能
- 为后续 CS 和 ECE 的“系统”课程做好准备
- 编译器、操作系统、网络、计算机体系结构、嵌入式系统、存储系统等。
- 成为更高效的程序员
五个真实的场景
场景一 整数不是整型,浮点数不是实数

整数不是整型,浮点数不是实数
- 示例一:
x*x >= 0?- 浮点数:
x*x确实大于 0 - 整数:
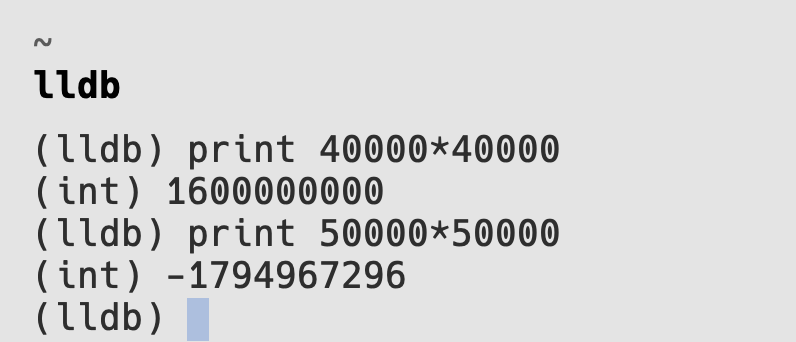
40000 * 40000 -> 160000000050000 * 50000 -> ??
- 使用 lldb 进行实验
- 浮点数:
- 示例二:
(x+y) +z = x + (y +z)?- Unsigned & Signed Int’s: Yes! 无符号数和有符号数:满足结合律
- 浮点数:
(1e20 + - 1e20) + 3.14 --> 3.141e20 + (-1e20 + 3.14) --> ??这两个表达式涉及到了浮点数的精度问题和加法的结合性。
对于任何有限的浮点数计算来说,安排操作的顺序往往都会导致稍有不同的结果,这是因为有限的浮点数只能近似表示真正的实数。它们不能精确表示像 1/10,1/3 和 π 这样的非常简单的数字。所以,小数位通常不能被完全依赖,特别是在做很多计算或跨几个数量级的计算时。在你给出的例子中,1e20 和 -1e20 相加,浮点数的精度损失会比加上 3.14 要大得多,所以 (1e20 + -1e20)+3.14 结果会很接近 3.14。
而 1e20 + (-1e20 + 3.14) 里, -1e20 + 3.14 的跨度非常大,导致 3.14 的部分在计算过程中的影响被 “吞噬”了,再与 1e20 相加,结果将会是 1e20。(注意,这只是个估计,具体结果可能会因为具体的浮点数实现方式而微微不同。)
这就是为什么改变浮点数加法的顺序会导致不同的结果的原因。尽管数学上 (a+b)+c 和 a+(b+c) 是相等的,但在有限浮点数计算中则不然。
计算机算术

- 不生成随机值
- 算术运算具有重要的数学特性
- 无法假设所有“通常”的数学属性
- 由于表示的有限性
- 整数运算满足“环”性质
- 交换律、结合律、分配律
- 浮点运算满足“排序”属性
- 单调性、符号值
- 观察
- 需要了解哪些抽象适用于哪些上下文
- 编译器编写者和认真的应用程序程序员的重要问题
场景二 你需要了解汇编

你需要了解汇编
- 有可能,您永远不会用汇编语言编写程序
- 编译器比你更好、更有耐心
- 但是:理解汇编是机器级执行模型的关键
- 程序在存在 bug 的情况下的行为
- 高级语言模型崩溃
- 调优程序性能
- 了解编译器完成/未完成的优化
- 了解程序效率低下的根源
- 实施系统软件
- 编译器以机器代码作为目标
- 操作系统必须管理进程状态
- 创建/对抗恶意软件
- ×86 汇编是首选语言!
- 程序在存在 bug 的情况下的行为
场景三 随机存取存储器是一种非物理抽象

随机存取存储器是一种非物理抽象
- 内存不是无限的
- 必须对其进行分配和管理
- 许多应用程序都是内存主导的
- 内存引用错误尤其有害
- 影响在时间和空间上都是遥远的
- 内存性能不统一
- 缓存和虚拟内存效应会极大地影响程序性能
- 使程序适应内存系统的特性可以显着提高速度使程序适应内存系统的特性可以显着提高速度
内存引用错误示例

结果:

在给出的结构中,a 是一个整数数组,
a[0]就是数组的第一个元素。a[0]的类型是 int。在大多数的现代系统中,int 通常是 4 字节(32 位),但这是依赖于具体的编译器和硬件的。如果你需要确定 int 的字节大小,一个常见的方式是使用 sizeof 运算符,例如 sizeof(int)。
所以,a[0]大概占用 4 字节,但可能会随着不同的编译器和硬件而变化。
a 中的每个元素都是 4 个字节,d 中的每个元素都是 8 个字节。
在内存中,数组元素会被连续地存储起来。在你提供的代码中,struct_t 有一个整型数组 a 和一个双精度浮点数 d。这个结构的内存布局具体取决于编译器以及目标硬件架构的内存对齐规则。
对于一个典型的 32 位的整数和 64 位的双精度浮点数(这取决于具体的编译器和硬件),可能的内存布局如下:
| a[0] (4 bytes) | a[1] (4 bytes) | padding (4 bytes) | d (8 bytes) |
请注意,我在中间插入了一个 4 字节的填充(padding)。这是因为一些硬件需要(或更高效的进行)特定类型的数据与特定的内存地址对齐(比如,双精度浮点数 d 需要与 8 字节边界对齐),所以编译器可能会自动做这样的填充。
在具有内存越界和填充的系统中,如果你试图为 a[2] 赋值,则可能会写入 d 的内存位置或其填充范围内,并导致 fun() 函数返回的值发生更改。这是未定义行为,它的结果可能因不同的编译器和优化选项而异。
这个结构体的具体布局可以通过结构体内存布局或内存对齐插入查询的 C 或 C++ 库来查看,但这超出了你的问题的范围。
总的来说,访问数组 a 的下标 2 是越界操作,因为数组 a 只定义了两个元素 a[0] 和 a[1],这可能会导致一些不可预知的行为,尤其是在 s 是 volatile 的时候。
建议:不要读取或写入数组的界限以外的数据,因为这可能会导致一些难以预测和诊断的错误。

- C 和 C++ 不提供任何内存保护
- 数组引用越界
- 无效的指针值
- 滥用 malloc/free
- 可能会导致讨厌的错误
- bug 是否有影响取决于系统和编译器
- 超距作用
- 损坏的对象在逻辑上与正在访问的对象无关
- bug 的影响可能在生成很久之后才被首次观察到
- 我该如何处理这个问题?
- 使用 Java、Ruby、Python、ML 进行编程…
- 了解可能发生的相互作用
- 使用或开发工具来检测引用错误(例如 Valgrind)
场景四 性能优于渐进复杂度

性能优于渐进复杂度
- 常数因素也很重要!
- 根据代码编写方式的不同,性能范围可能轻松达到 10:1。
- 必须在多个级别进行优化:算法、数据表示、过程和循环
- 必须了解系统才能优化性能
- 程序如何编译和执行
- 如何衡量程序性能并识别瓶颈
- 如何在不破坏代码模块化性和通用性的情况下提高性能
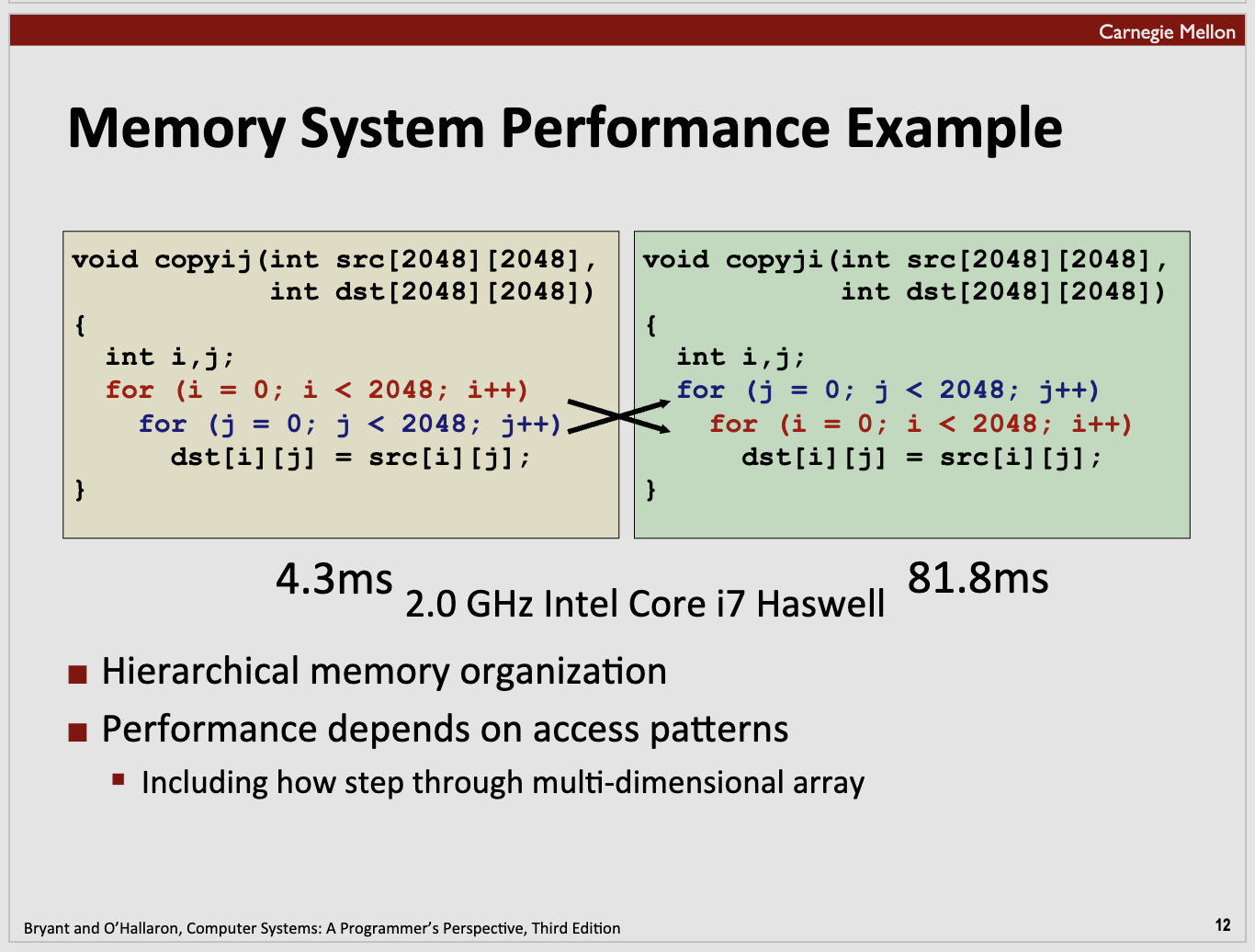
- 分层内存组织
- 性能取决于访问模式
- 包括如何逐步遍历多维数组
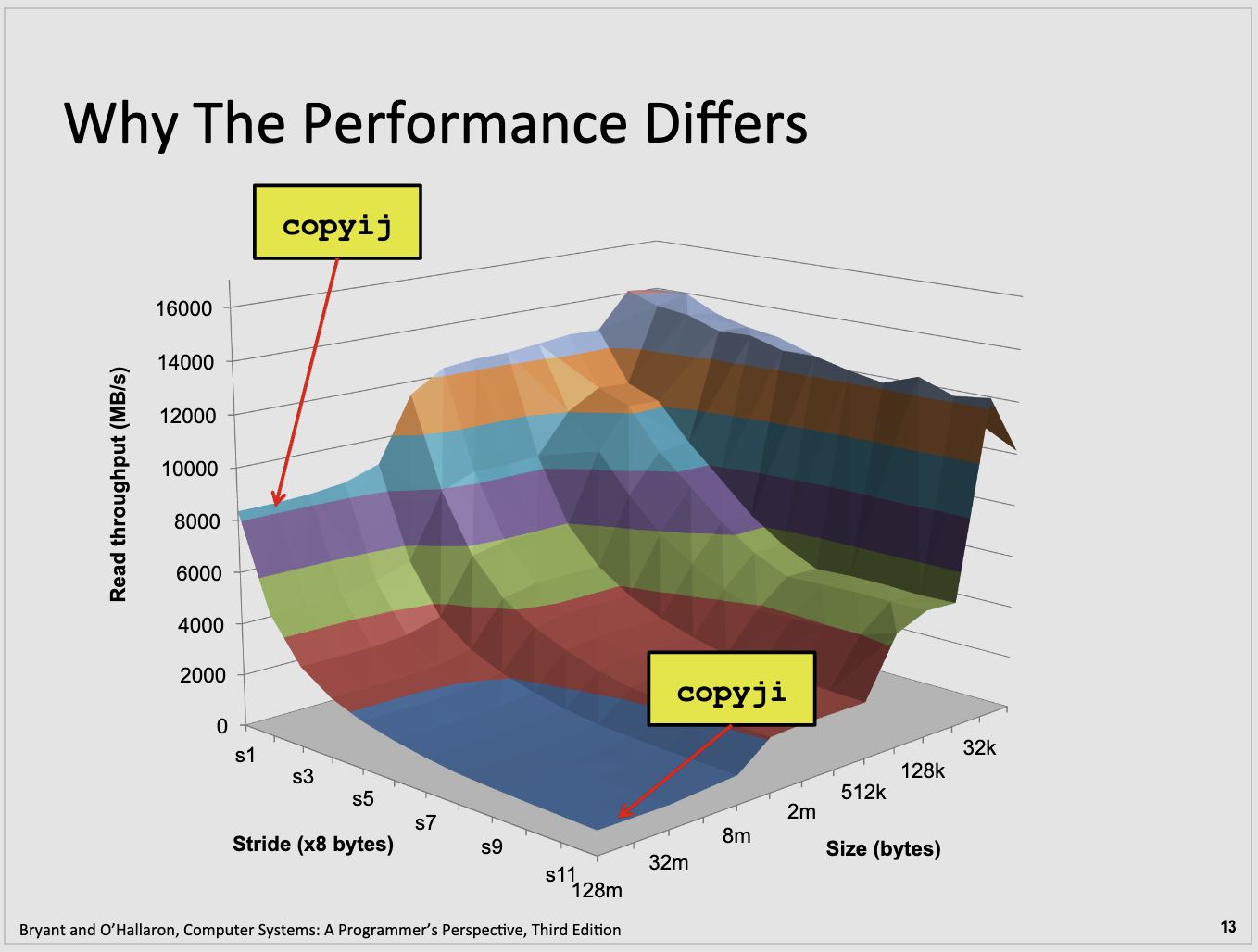
这两个函数的区别在于它们访问数组的顺序。
copyij 函数是沿着每一行从左到右走,走完一行再下到下一行,就像我们阅读文字一样。首先看完第一行的内容,然后再到下一行,再下一行等等。
copyji 函数则是沿着每一列从上到下走,走完一列再移到下一列,就像雨水从上往下落,然后再从左到右扩展。
在计算机的内存中,先走行的方法(也就是 copyij 做的事情)是最有效的,因为计算机先存储数组的第一行,然后是第二行,以此类推。这使得计算机能更好地预测你将要看哪一块数据,并把它提前取到手边,这样就把等待数据的时间缩短了。
然而在 copyji 函数中,它是一列列的对数组进行操作,这使得计算机取数据的过程效率变低,因为每次都只取一个,而不是一大块,这样就要花更多的时间等待数据被取出来。这就好比你在一个图书馆里,一次只拿一本书而不是一叠书,你就需要多次跑动来回才能取齐。而 copyij 就好比你一次性取了一整叠书,所以要跑的次数就少了。
场景五 计算机不仅仅是执行程序

计算机不仅仅是执行程序
- 他们需要输入和输出数据
- I/O 系统对程序的可靠性和性能至关重要
- 他们通过网络相互通信
- 在网络存在的情况下,会出现许多系统级问题。
- 由自主进程进行的并发操作
- 应对不可靠媒体
- 跨平台兼容性
- 复杂的性能问题
- 在网络存在的情况下,会出现许多系统级问题。
课程体系
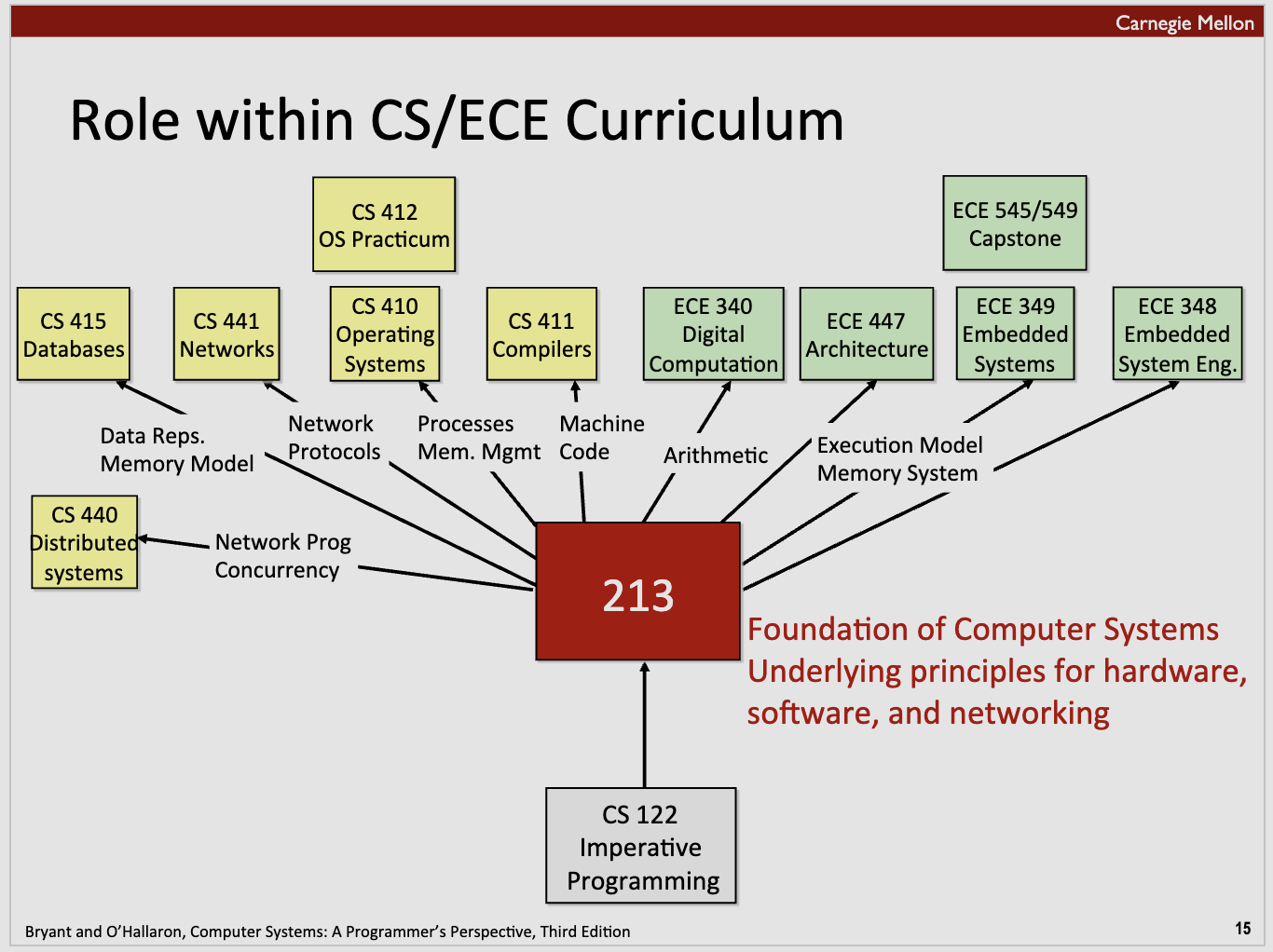
课程前景

- 大多数系统课程都以建设者为中心
- 计算机体系结构
- 在 Verilog 中设计流水线处理器
- 操作系统
- 实现操作系统的示例部分
- 编译器
- 为简单语言编写编译器
- 网络
- 实现和模拟网络协议
- 计算机体系结构
课程用书

- csapp 第三版
- The C Programming Language 第二版
课程组成部分

- 讲课
- 高级概念
- 背诵的内容
- 应用概念、重要的实验室工具和技能、讲座的澄清、考试范围
- 7 次实验
- 课程核心
- 每周 1 到 2 次
- 提供对系统某个方面的深入理解
- 编程和测量
- 考试
- 测试您对概念和数学原理的理解
教学大纲
程序和数据

- 主题
- 位运算、算术、汇编语言程序
- C 控制和数据结构的表示
- 包括架构和编译器方面
- 作业
- L1(数据实验):操作位
- L2(炸弹实验):拆除二进制炸弹
- L3(攻击实验):代码注入攻击的基础知识
内存层次结构

- 主题
- 内存技术、内存层次结构、缓存、磁盘、局部性
- 包括架构和操作系统方面
- 作业
- L4(缓存实验):构建缓存模拟器并针对局部性进行优化。了解如何在程序中利用局部性。
独特的控制流

- 主题
- 硬件异常、进程、进程控制、Unix 信号、非本地跳转
- 包括编译器、操作系统和体系结构方面
- 作业
- L5 (tsh 实验):编写您自己的 Unix shell。首次介绍并发性
虚拟内存

- 主题
- 虚拟内存、地址转换、动态存储分配
- 包括架构和操作系统方面
- 作业
- L6 (分配内存实验):编写自己的分配内存包。真实感受系统级编程
网络和并发

- 主题
- 高级和低级 I/O、网络编程
- 互联网服务、网络服务器
- 并发、并发服务器设计、线程
- I/O 多路复用与选择
- 包括网络、操作系统和架构方面
- 作业
- L7 (代理实验):编写您自己的 Web 代理。了解网络编程以及有关并发和同步的更多信息。
